Extraer Texto de un PDF en 2025: Solución Fácil y Rápida

Resumen
¿Quieres extraer texto de un PDF de forma rápida y sencilla? En esta guía te mostramos cómo hacerlo gratis, con herramientas fáciles y tecnología OCR. Descubre métodos prácticos y ahorra tiempo en tus tareas. ¡Sigue leyendo y mejora tu productividad!

Índice


Pasos para copiar y pegar texto página por página


Copiar texto de un PDF da como resultado caracteres corruptos
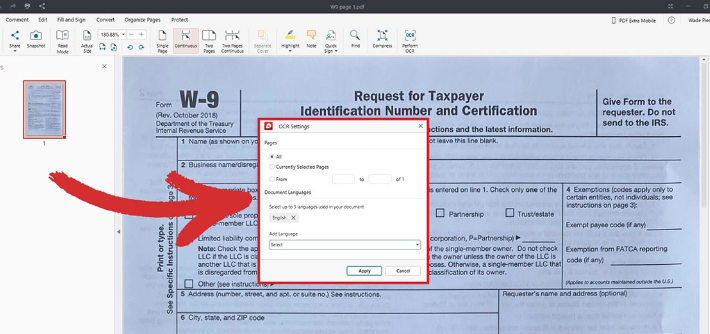
Archivos PDF escaneados

Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Varias funciones de edición Cifrado/descifrado/división/fusión/marca de agua, etc.
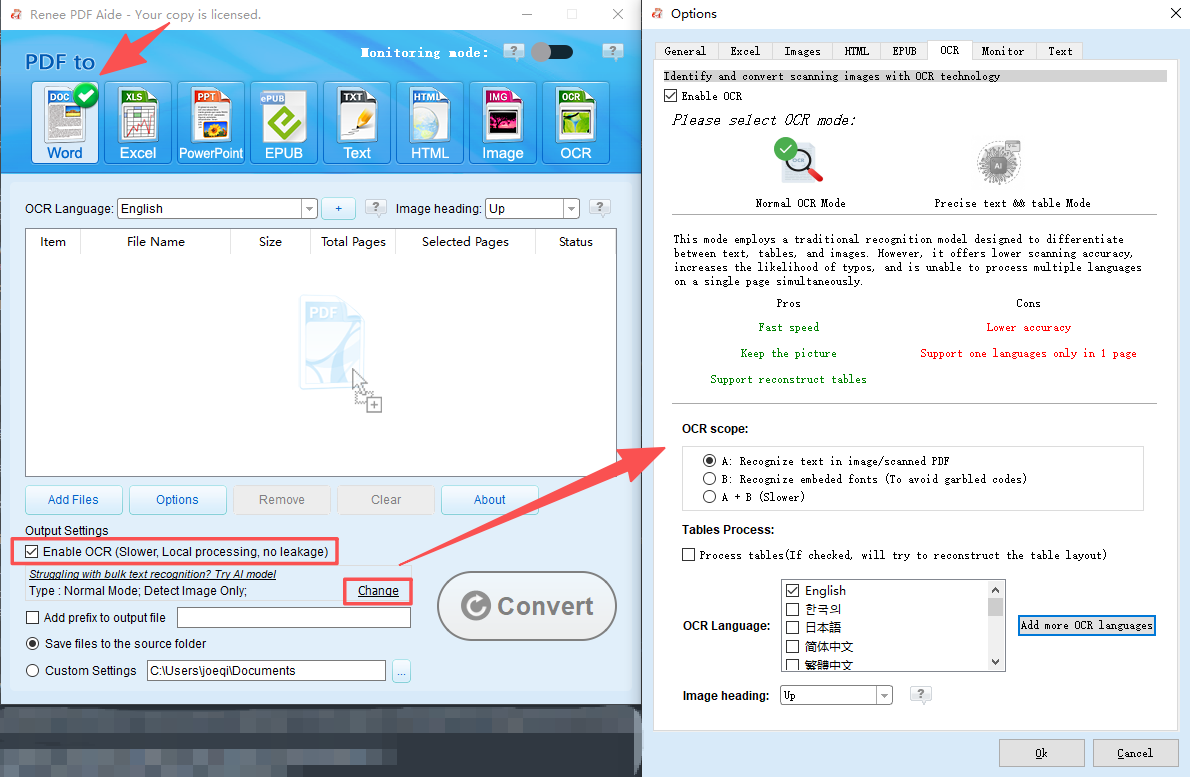
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
La edición/conversión es rápida Edite/convierta rápidamente varios archivos al mismo tiempo.
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Cómo usar la IA para la extracción de texto
Extract all text from this image and do not summarize the text.
Extract all text from this pdf file.

En muchos casos, los usuarios deben capturar manualmente las páginas una por una, lo que consume mucho tiempo y es propenso a errores. Para cargas de trabajo más grandes o para uso profesional, el software de escritorio dedicado sigue siendo la opción más fiable y eficiente.
📊 Gestión de PDF: Planes gratuitos vs. de pago (Actualización 2025)
| Plataforma | Versión gratuita | Versión de pago / Premium | Soporte de conversión de PDF | Formatos de salida | Mejoras de IA-OCR 2025 |
|---|---|---|---|---|---|
Microsoft Copilot | Sube PDF de hasta 50 páginas; divide archivos grandes. Se integra con Edge para un OCR rápido. | Microsoft 365: Páginas ilimitadas, extracción de tablas con IA. | ❌ Sin conversión directa, pero exporta a JSON a través de API. | Texto sin formato, JSON | Cognitive Services v3.1: 98% de precisión para documentos escaneados. |
ChatGPT (OpenAI) | Sin subida directa; pega texto o captura de pantalla. | Plus/Team: Sube hasta 300 páginas; OCR automático para imágenes. | ❌ Solo resume; usa plugins para exportar. | Texto sin formato, listas con viñetas | Integración con LlamaParse: Maneja PDF multilingües (p. ej., inglés+hindi). |
Grok (xAI) | Sube ~50 páginas; búsqueda semántica de texto. | Premium: ~200 páginas, procesamiento por lotes. | ❌ Solo texto sin formato. | Texto sin formato | OCR mejorado para escaneos de baja calidad; centrado en la privacidad. |
¿Qué es Renee PDF Aide?
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Varias funciones de edición Cifrado/descifrado/división/fusión/marca de agua, etc.
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
La edición/conversión es rápida Edite/convierta rápidamente varios archivos al mismo tiempo.
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Extraer texto a Word

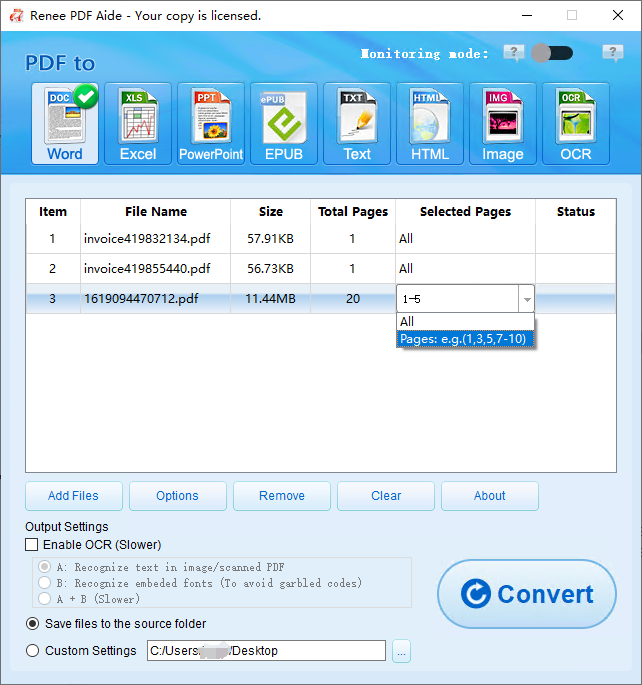

Extraer texto a Excel
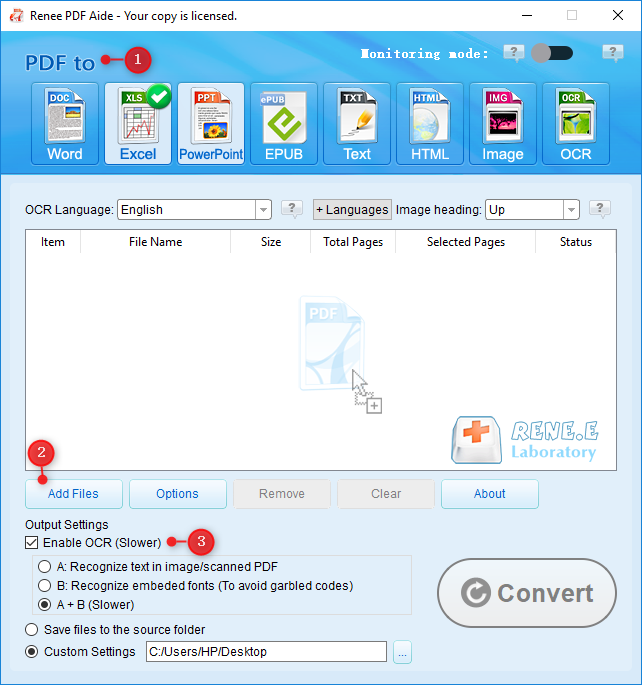
Extraer texto a PowerPoint
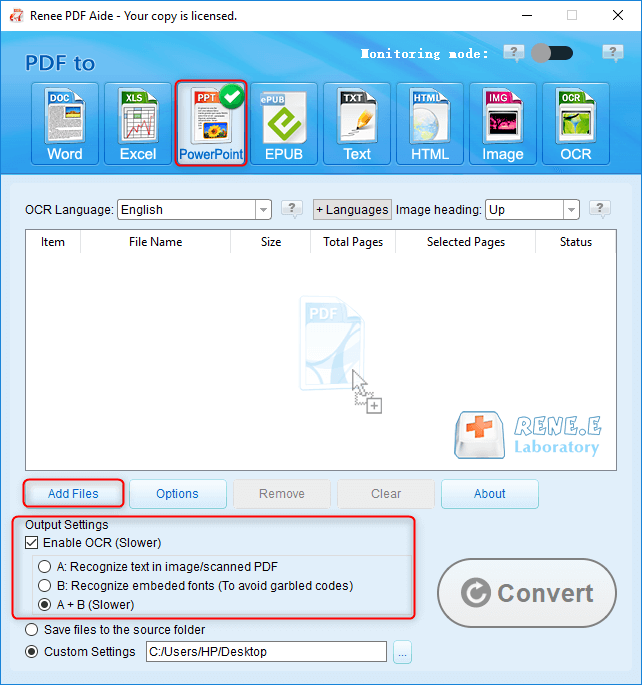
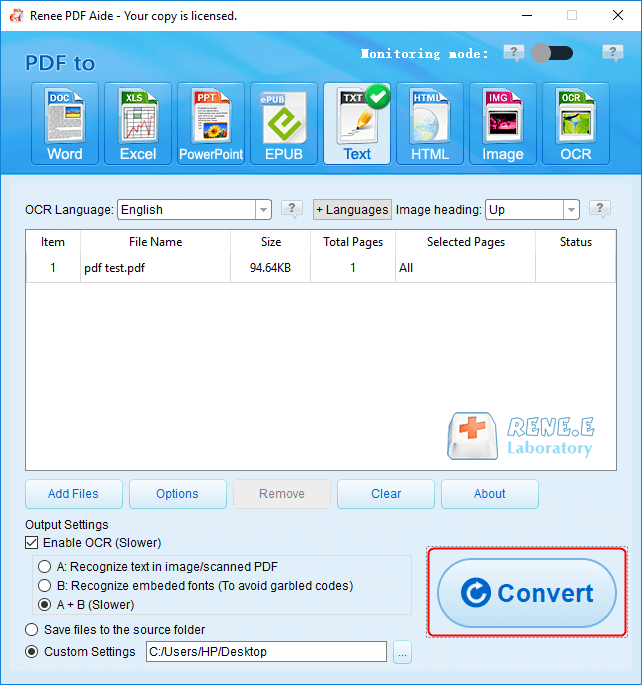
Extraer texto a TXT

| Herramienta | Características | Limitaciones |
|---|---|---|
PDF Candy | Conversión gratuita de PDF a TXT, OCR automático para archivos escaneados, interfaz fácil de usar. Ideal para extraer listas de productos de catálogos. | Límites de tamaño de archivo (~100 MB), anuncios en la versión gratuita, más lento en horas punta, riesgos de privacidad por subidas a servidores. |
PDF2Go | No requiere registro, compatible con móviles, conversión rápida a TXT con OCR. Genial para notas rápidas de PDF de reuniones. | Tamaño de archivo limitado, posible exposición de datos, pérdida ocasional de formato, requiere internet. |
Ejemplo de script de Python
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Página {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Página {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Formato de salida no compatible. Utiliza 'txt' o 'docx'.")
return output_file
except Exception as e:
print(f"Error al procesar el PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Texto extraído a: {result}")✅ Ventajas: Gratis, personalizable
❌ Desventajas: Requiere configuración
hin+eng para un OCR preciso. Guárdalo como TXT para texto sin formato o en Word para una edición con formato.| Tipo de usuario | Mejor método | Ventajas | Siguiente paso |
|---|---|---|---|
Principiante | Copiar y pegar o herramientas en línea | Sencillo, sin coste ni necesidad de conocimientos. | Abre hoy tu PDF en Foxit Reader. |
Profesional | Renee PDF Aide | Conversiones rápidas a Word/Excel, seguro y sin conexión. | Descarga la versión de prueba desde el sitio oficial. |
Experto en tecnología | Python con OCR | Automatizado, escalable para grandes volúmenes de datos. | Instala las dependencias y prueba el código. |
Usuario móvil | Asistentes de IA | Funciona en cualquier lugar con internet. | Prueba ChatGPT Plus para subir archivos. |
¿Qué pasa si el texto extraído está corrupto o incompleto?
¿Son seguras las herramientas en línea para PDF sensibles?
¿Puedo extraer texto de PDF cifrados?
¿Cómo manejo PDF grandes (p. ej., más de 500 páginas)?
¿Cómo extraigo texto de PDF multilingües?
hin+eng) para una extracción precisa de PDF bilingües.¿La extracción de texto mantiene el formato original del PDF?
Posts Relacionados :
Renee PDF Aide no funciona: cómo solucionar el error de AVX y OCR

25-08-2025
Alberte Vázquez : Descubre cómo las Advanced Vector Extensions (AVX) mejoran la velocidad y precisión del OCR en Renee PDF Aide....
Convierte PDF a Excel fácilmente: guía rápida y eficaz
10-06-2025
Alberte Vázquez : Descubre cómo importar fácilmente datos de tablas desde PDFs a Excel. Te mostramos paso a paso cómo hacerlo...
Cómo pasar PDF a Excel o Google Sheets fácilmente: Solución paso a paso

10-06-2025
Hernán Giménez : Descubre cómo convertir fácilmente archivos PDF en hojas de Excel con Google Sheets. Aprende a preparar tus archivos,...
Cómo Pasar Texto de PDF a Excel Fácilmente: Soluciones Prácticas

10-06-2025
Estella González : Descubre cómo extraer texto de PDF a Excel de forma sencilla y eficiente. Te mostramos opciones gratuitas, herramientas...
Comentarios de los usuarios
Dejar un comentario