Convierte PDF a DOCX con Python: scripts por lotes, librerías y herramientas fiables en España

Resumen
Aprende a convertir PDF a DOCX con Python con pdf2docx y PyMuPDF, y descubre alternativas de escritorio. Te mostramos ejemplos para convertir en lote, aplicar OCR y automatizar la conversión con monitorización de carpetas para un flujo de trabajo fiable. Sigue leyendo para ver la comparativa definitiva.


| Tipo de problema | Causa típica | Comprobación previa / Diagnóstico |
|---|---|---|
PDFs escaneados | Sin texto seleccionable | Abre el PDF e intenta resaltar texto; si no se resalta nada, se necesita OCR |
Tablas/diseños complejos | pdf2docx no tiene un motor de diseño | Convierte una página primero y verifica si hay columnas desplazadas |
Fuentes incrustadas / texto confuso | Subconjunto de fuentes o codificación no estándar | Revisa el DOCX en busca de □ o símbolos aleatorios |
Fallos en lotes grandes | Conflictos de memoria o dependencias | Prueba con 5–10 archivos; vigila el uso de RAM |

| Enfoque | Ideal para | Limitación principal |
|---|---|---|
pdf2docx | Conversiones rápidas de PDFs digitales | Débil con diseños complejos; sin OCR |
PyMuPDF + python-docx | Control total y lógica de extracción personalizada | Requiere codificación intensiva para la reconstrucción del diseño |
pdfplumber | PDFs centrados en tablas | Sin salida DOCX; solo extracción de texto |
Pandoc | Canales programables; flujos de trabajo multiformato | La calidad de PDF→DOCX depende de los lectores LaTeX/PDF |
LibreOffice CLI | Automatización por lotes; conversión sin interfaz | La fidelidad del diseño varía; sin OCR |
| Característica | Soporte |
|---|---|
PDF→DOCX directo | Sí |
OCR | No |
Fuentes incrustadas | Parcial |
Diseños complejos | Moderado |
Automatización | Sí |
Formularios XFA | No |
| Característica | Soporte |
|---|---|
PDF→DOCX directo | No (codificación manual) |
OCR | No (se necesita OCR externo) |
Fuentes incrustadas | Solo lectura |
Diseños complejos | Alto control, manual |
Automatización | Excelente |
Formularios XFA | No |
| Característica | Soporte |
|---|---|
PDF→DOCX directo | No |
OCR | No |
Fuentes incrustadas | No |
Diseños complejos | Bueno para tablas |
Automatización | Sí |
Formularios XFA | No |
| Característica | Soporte |
|---|---|
PDF→DOCX directo | Sí (mediante LaTeX) |
OCR | No |
Fuentes incrustadas | No |
Diseños complejos | Limitado |
Automatización | Excelente |
Formularios XFA | No |
| Característica | Soporte |
|---|---|
PDF→DOCX directo | Sí |
OCR | No |
Fuentes incrustadas | Parcial |
Diseños complejos | Moderado |
Automatización | Excelente |
Formularios XFA | No |

Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Varias funciones de edición Cifrado/descifrado/división/fusión/marca de agua, etc.
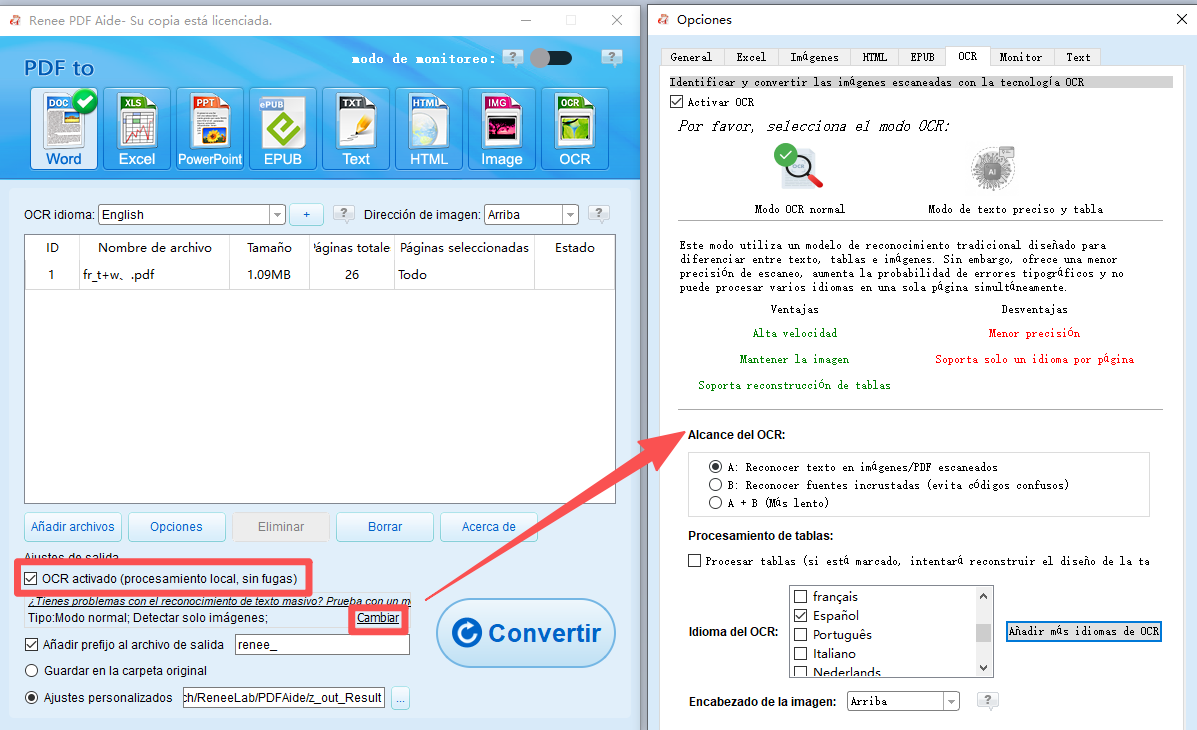
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
La edición/conversión es rápida Edite/convierta rápidamente varios archivos al mismo tiempo.
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Ventajas clave incluyen

Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Varias funciones de edición Cifrado/descifrado/división/fusión/marca de agua, etc.
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
La edición/conversión es rápida Edite/convierta rápidamente varios archivos al mismo tiempo.
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Pasos
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Limitaciones
- Control y personalización total del código
- Gratuito para PDFs nativos simples
- Fácil integración en canales de Python existentes
Cons:
- Sin OCR integrado para documentos escaneados
- Las tablas e imágenes complejas a menudo se desalinean
- Requiere herramientas externas para la ejecución programada
- Depuración intensiva necesaria para diferentes diseños de PDF
| Caso de uso | Herramienta recomendada |
|---|---|
Prueba rápida en 1–2 PDFs simples | Script de Python pdf2docx |
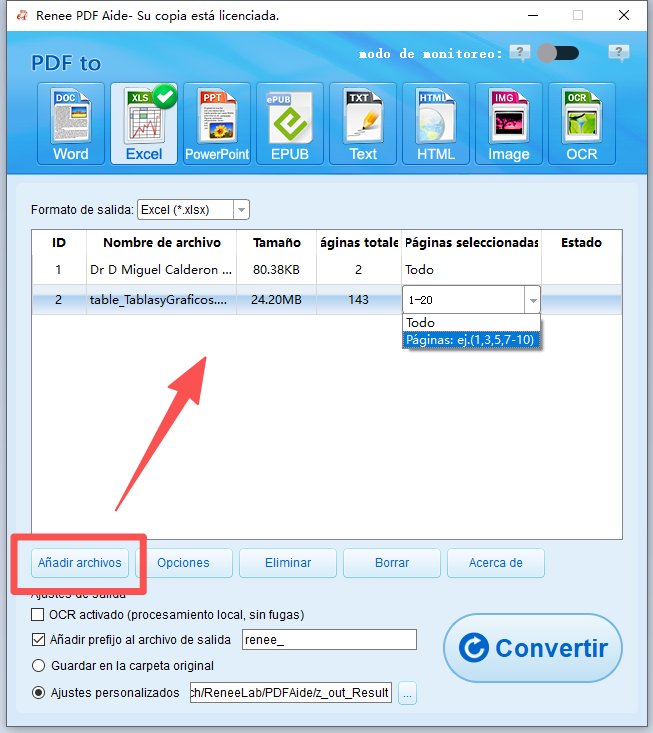
PDFs escaneados o diseños complejos | Renee PDF Aide con OCR |
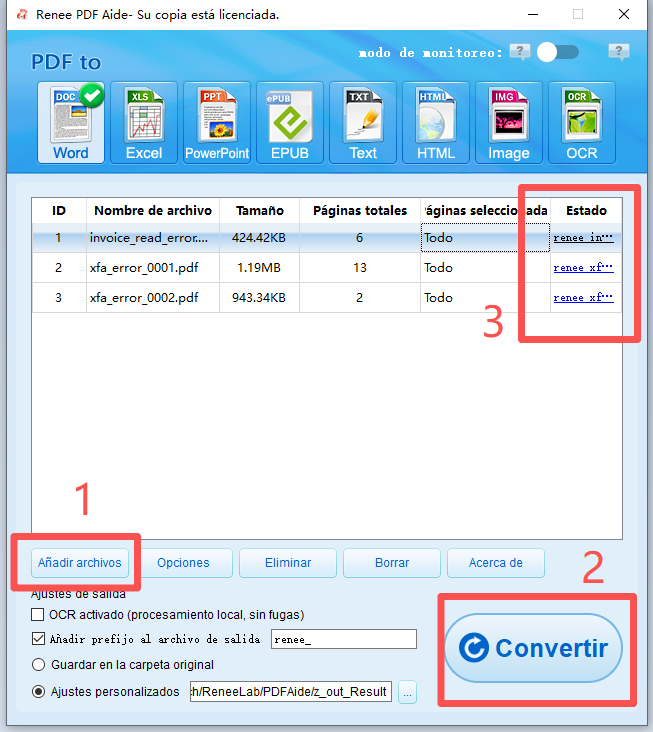
Conversión por lotes (más de 50 archivos) | Renee PDF Aide (lote + modo de monitorización) |
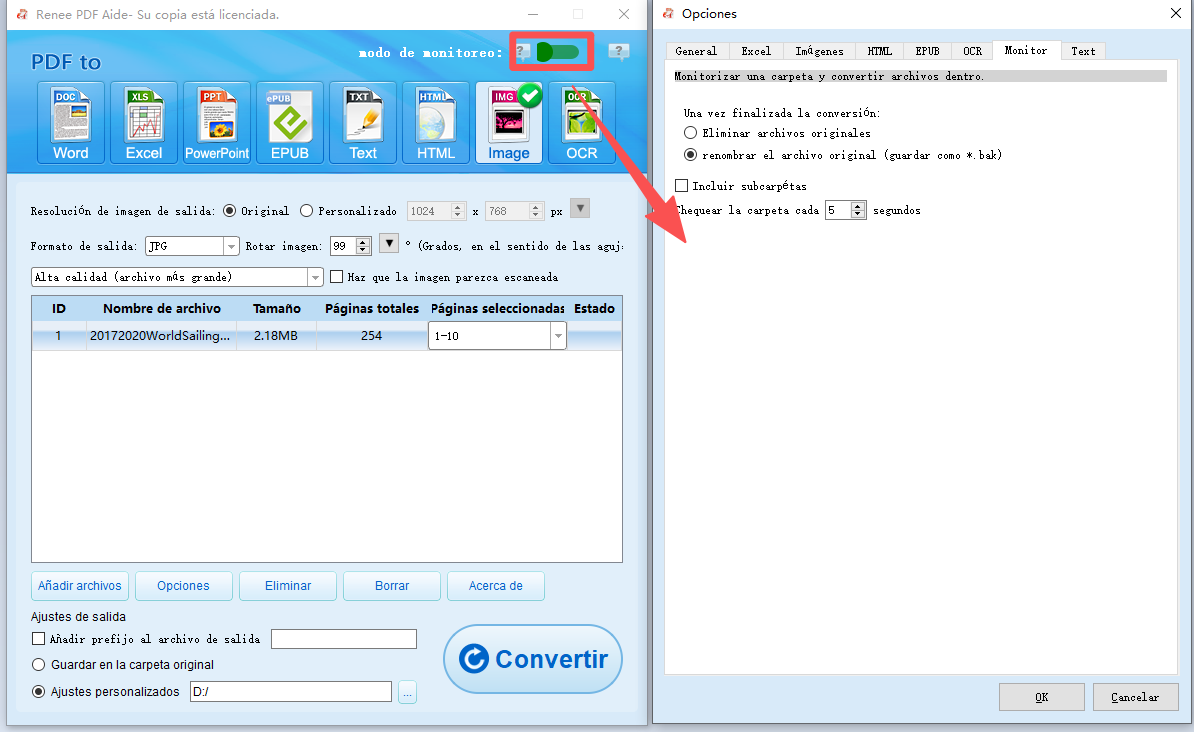
Conversiones programadas nocturnas | Modo de monitorización de Renee PDF Aide |
Control total del código + PDFs simples | Script personalizado PyMuPDF + watchdog |
¿Puede Renee PDF Aide manejar PDF escaneados que los scripts de Python no pueden leer?
¿Por qué pdf2docx pierde el formato de mis tablas o la alineación de columnas?
¿Cuál es el tamaño máximo de lote o límite de páginas en Renee PDF Aide?
¿Puedo convertir PDF protegidos con contraseña a DOCX con Python o Renee PDF Aide?
¿Renee PDF Aide funciona con formularios XFA (PDFs bancarios/gubernamentales)?

Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Varias funciones de edición Cifrado/descifrado/división/fusión/marca de agua, etc.
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
La edición/conversión es rápida Edite/convierta rápidamente varios archivos al mismo tiempo.
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Convierte a formatos editables Word/Excel/PowerPoint/Texto/Imagen/HTML/EPUB
Soporte OCR extrae texto de PDFs escaneados, imágenes y fuentes incrustadas
Compatible con Windows 11/10/8/8.1/Vista/7/XP/2000
Posts Relacionados :
¿Necesitas extraer tablas de PDF? Descubre gratis las mejores herramientas e IA

28-10-2025
Alberte Vázquez : Descubre cómo extraer tablas de PDF de forma rápida y sencilla en 2025 con las mejores herramientas gratuitas...
Extraer Texto de un PDF en 2025: Solución Fácil y Rápida

03-10-2025
Camila Arellano : ¿Quieres extraer texto de un PDF de forma rápida y sencilla? En esta guía te mostramos cómo hacerlo...
Comentarios de los usuarios
Dejar un comentario